


A brief discussion on the scheduling mechanism of Goroutine
Contents
1. What is Goroutine?
In the Go language, each concurrent execution unit is called a goroutine. The opposite of concurrency is serial, that is, the code is executed line by line in order. Goroutine provides the Go language with the ability to concurrently program.
When a program starts, its main function runs in a separate goroutine, we call it main goroutine, and a new goroutine is created using the go statement. Syntactically, a go statement is an ordinary function or method call preceded by the keyword go. The go statement will cause the function in the statement to run in a newly created goroutine.
f() // call f(); wait for it to return go f() // create a new goroutine that calls f(); don't wait
It is very simple to implement concurrent programming through coroutines in the Go language: we can enable multiple coroutines in one processing process through the keyword go, and then complete different subtasks in different coroutines.
Goroutine can be regarded as a layer of abstraction added to thread. It is user-mode and more lightweight. Because of this layer of abstraction, Gopher will not directly face threads. The operating system, on the contrary, cannot see the existence of goroutine. It can just execute the thread with peace of mind. The thread is the basic unit of its scheduling.
What is the difference between Goroutine and thread?
1. Memory usage:
The stack memory consumption of creating a goroutine is 2 KB. During actual operation, if the stack space is not enough, it will be automatically expanded. Creating a thread requires 1 MB of stack memory.
For an HTTP Server built in Go, it is very easy to create a goroutine to handle each incoming request. And if you use a service built in a language that uses threads as concurrency primitives, such as Java, it would be too wasteful of resources to correspond to one thread for each request, and OOM errors (Out Of Mermory Error) will soon occur.
2. Creating and destroying
Thread creates and destroys huge consumption, because it has to deal with the operating system at the kernel level. The usual solution is the thread pool. Because goroutine is managed by Go runtime, the creation and destruction consumption is very small, and it is user-level.
3.
When switching threads, various registers need to be saved for future recovery: including all registers, 16 general-purpose registers, program counter, stack pointer, segment register, 16 XMM registers, FP coprocessor, 16 AVX Registers, all MSRs, etc.
Saving and restoring goroutine only requires three registers: program counter, stack pointer and DX register, and does not need to fall into the operating system kernel layer.
Generally speaking, thread switching will consume 1000-1500 nanoseconds, and Goroutine switching is about 200 ns. In comparison, goroutines switching cost is much smaller than threads.
2. Thread concurrency model
Threads are the smallest scheduling unit of the operating system kernel. The goroutine we mentioned above is also based on threads. According to the corresponding relationship between user threads and kernel threads, it is divided into the following concurrency models:
1. User-level thread model
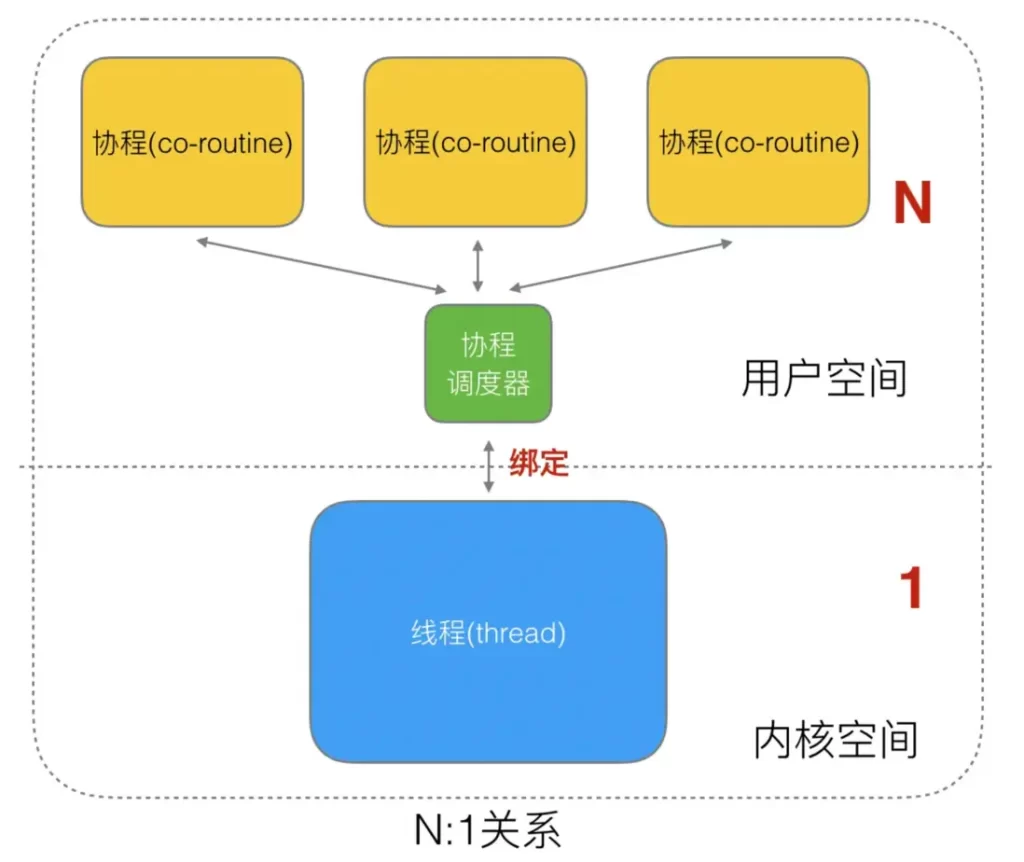
User threads and kernel threads have a many-to-one (N:1) mapping model, that is, all threads created in a process are only dynamically bound to the same kernel thread at runtime. The coroutine library gevent implemented in Python belongs to this way.
The creation, destruction of these threads and the coordination between multi-threads are all handled by the user’s own thread library without resorting to system calls. This implementation method is very lightweight compared to kernel-level threads. The consumption of system resources will be much smaller, so the number of threads that can be created and the cost of context switching will also be much smaller. But this model has an original sin: it cannot achieve true concurrency. Suppose that a user thread on a user process is interrupted by the CPU due to a blocking call (such as I/O blocking) (preemptive scheduling) , then all threads in the process are blocked and the entire process is suspended.
2. Kernel-level thread model
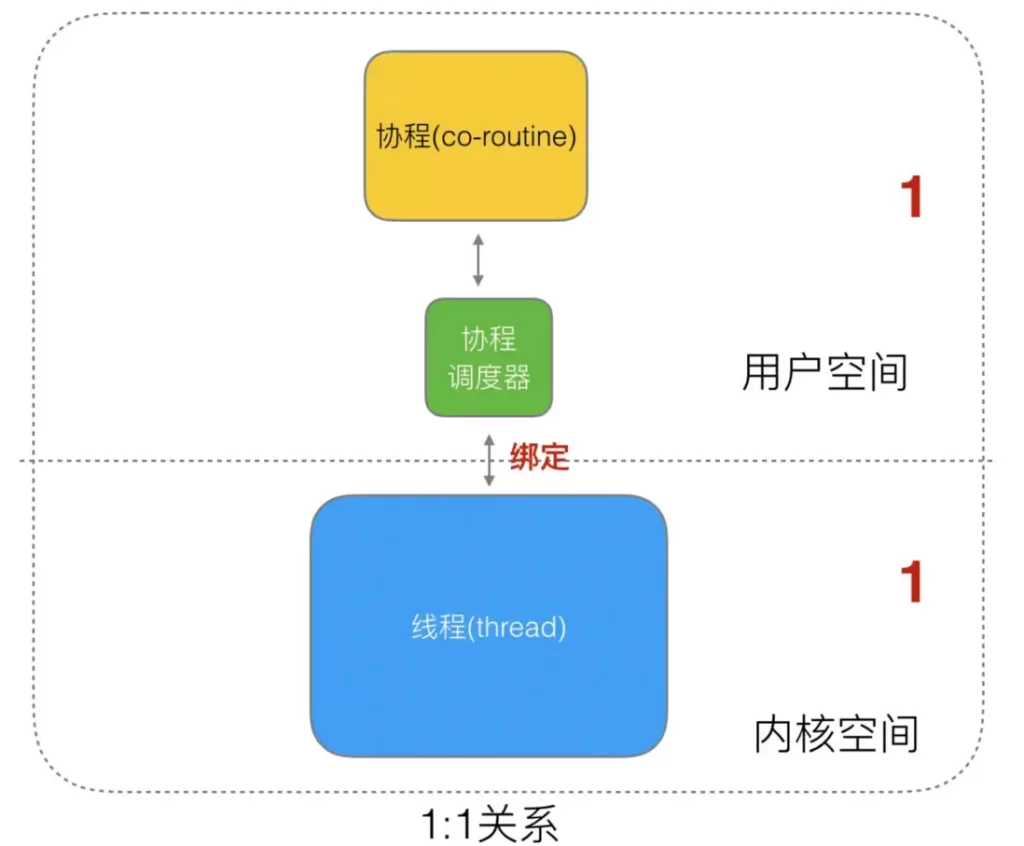
User threads and kernel threads KSE have a one-to-one (1:1) mapping model, that is, each user thread is bound to an actual kernel thread, and thread scheduling is completely handed over to the operating system kernel. Java threads This is achieved based on this.
The advantage of this model is that it is simple to implement. It directly relies on the threads and scheduler of the operating system kernel, so the CPU can quickly switch scheduling threads, so multiple threads can run at the same time. Therefore, compared with the user-level thread model, it truly achieves parallel processing. ; But its disadvantage is that because it directly relies on the operating system kernel to create, destroy, and context switch and schedule between multiple threads, resource costs increase significantly and have a great impact on performance.
3. Two-level thread model
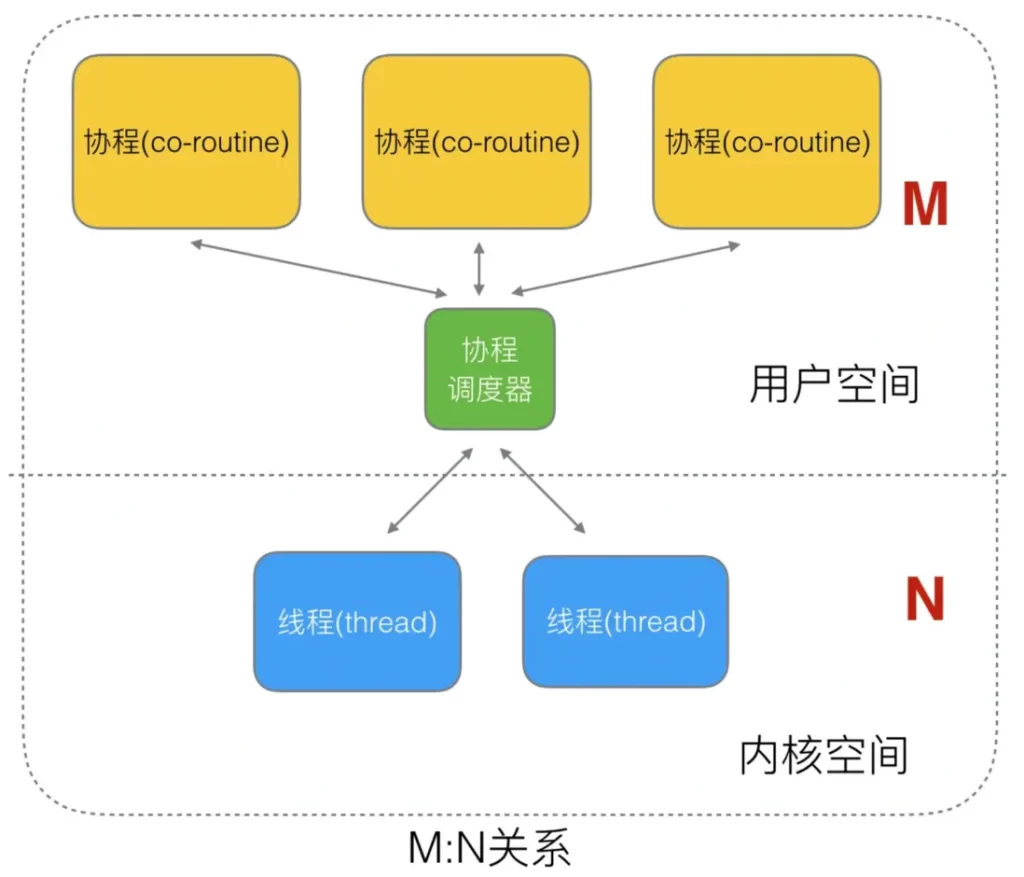
User threads and the kernel are a many-to-many (N:M) mapping model. This model maximizes the strengths and avoids the weaknesses of the previous two models: First, unlike the user-level thread model, a process in the two-level thread model can be associated with multiple kernel threads. , that is to say, multiple threads in a process can each bind their own KSE, which is similar to the kernel-level thread model; secondly, it is different from the kernel-level thread model in that the threads in its process are not unique to the KSE. Instead, multiple user threads can be mapped to the same KSE. When a KSE is scheduled out of the CPU by the kernel due to the blocking operation of its bound thread, the remaining user threads in its associated process can be re-bound to other KSEs. scheduled operation.
The implementation of this model is relatively complex. The runtime scheduler in the Go language uses this implementation scheme to realize the dynamic association between Goroutine and KSE. However, the implementation of the Go language is more advanced and elegant; why is this model called two class? That is, the user scheduler implements “scheduling” from user threads to KSE, and the kernel scheduler implements “scheduling” from KSE to the CPU.
3. The role of Go scheduler
When it comes to “scheduling”, the first thing we think of is the scheduling of processes and threads by the operating system. The operating system scheduler will schedule multiple threads in the system to run on the physical CPU according to a certain algorithm.
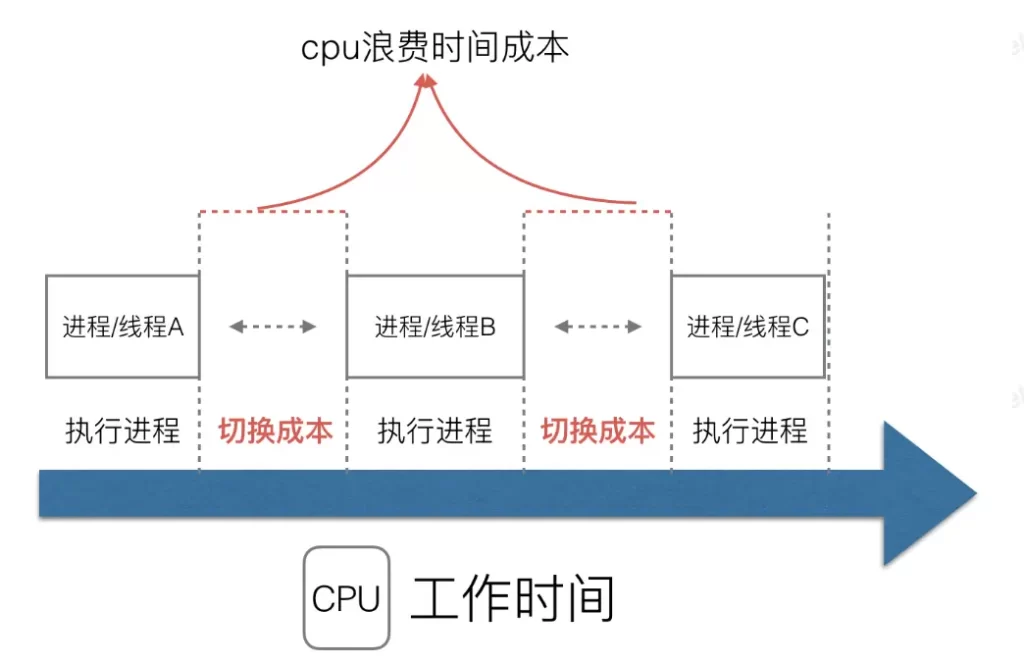
This traditional way of supporting concurrency has many shortcomings:
the cost of a thread is much smaller than that of a process, but we still cannot create a large number of threads, because in addition to the resources occupied by each thread, the more operations the thread opens, The cost of system scheduling switching is even greater;
A Go program is just a user-level program to the operating system. It only has threads in its eyes, and it does not even know the existence of Goroutine. The program that puts these goroutines on the “CPU” for execution according to a certain algorithm is called a goroutine scheduler or goroutine scheduler. At the operating system level, the “CPU” resource that Thread competes for is the real physical CPU, but at the Go program level, the “CPU” resource that each Goroutine competes for is the operating system thread.
At this point, the task of the goroutine scheduler is clear:
the goroutine scheduler reduces the memory overhead of frequent thread switching by using threads equal to the number of CPUs, and at the same time, executes additional lower-cost Goroutine on each thread to reduce the cost of the operating system and hardware. load.
Workflow
+-------------------- sysmon ---------------//------+
| |
| |
+---+ +---+-------+ +--------+ +---+---+
go func() ---> | G | ---> | P | local | <=== balance ===> | global | <--//--- | P | M |
+---+ +---+-------+ +--------+ +---+---+
| | |
| +---+ | |
+----> | M | <--- findrunnable ---+--- steal <--//--+
+---+
|
mstart
|
+--- execute <----- schedule
| |
| |
+--> G.fn --> goexit --+
1. The go func() statement creates G.
2. Put G into P's local queue (or balance it to the global queue).
3. Wake up or create a new M to perform tasks.
4. Enter the scheduling loop
5. Try your best to obtain executable G and execute it
6. Clean up the scene and re-enter the scheduling cycle
4. Go scheduler model and evolution process
1. GM model
On March 28, 2012, Go 1.0 was officially released. In this version, each goroutine corresponds to an abstract structure in the runtime: G, and the os thread is abstracted into a structure: M.
M must access the global G queue if it wants to execute and put it back into G, and there are multiple M’s. That is, multiple threads accessing the same resource need to be locked to ensure mutual exclusion/synchronization, so the global G queue is protected by a mutex lock.
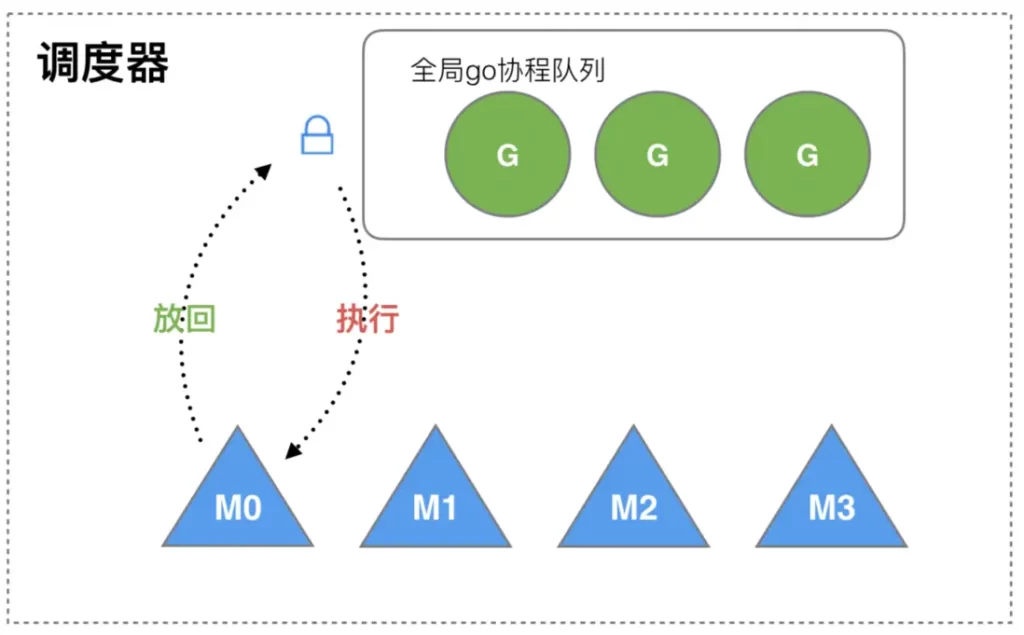
Although this structure is simple, there are many problems:
1. All goroutine-related operations, such as creation, rescheduling, etc., must be locked;
2. The transfer of M to G will cause delays and additional system load. For example, when G contains the creation of a new coroutine, M creates G1. In order to continue executing G, G1 needs to be handed over to M1 for execution, which also causes poor locality. Because G1 and G are related, it is best to put Execute on M, not other M1.
3. System calls (CPU switching between M) lead to frequent thread blocking and unblocking operations, which increases system overhead.
2. GPM model
The GPM scheduling model and work stealing algorithm were implemented in Go 1.1. This model is still used today:
in the new scheduler, in addition to M (thread) and G (goroutine), P (Processor) was introduced. P is a “logical Processor”. In order for each G to actually run, it first needs to be assigned a P (enter P’s local queue). For G, P is the “CPU” that runs it. It can be said: G only has P in his eyes. But from the perspective of Go scheduler, the real “CPU” is M. Only by binding P and M can G in P’s runq actually run.
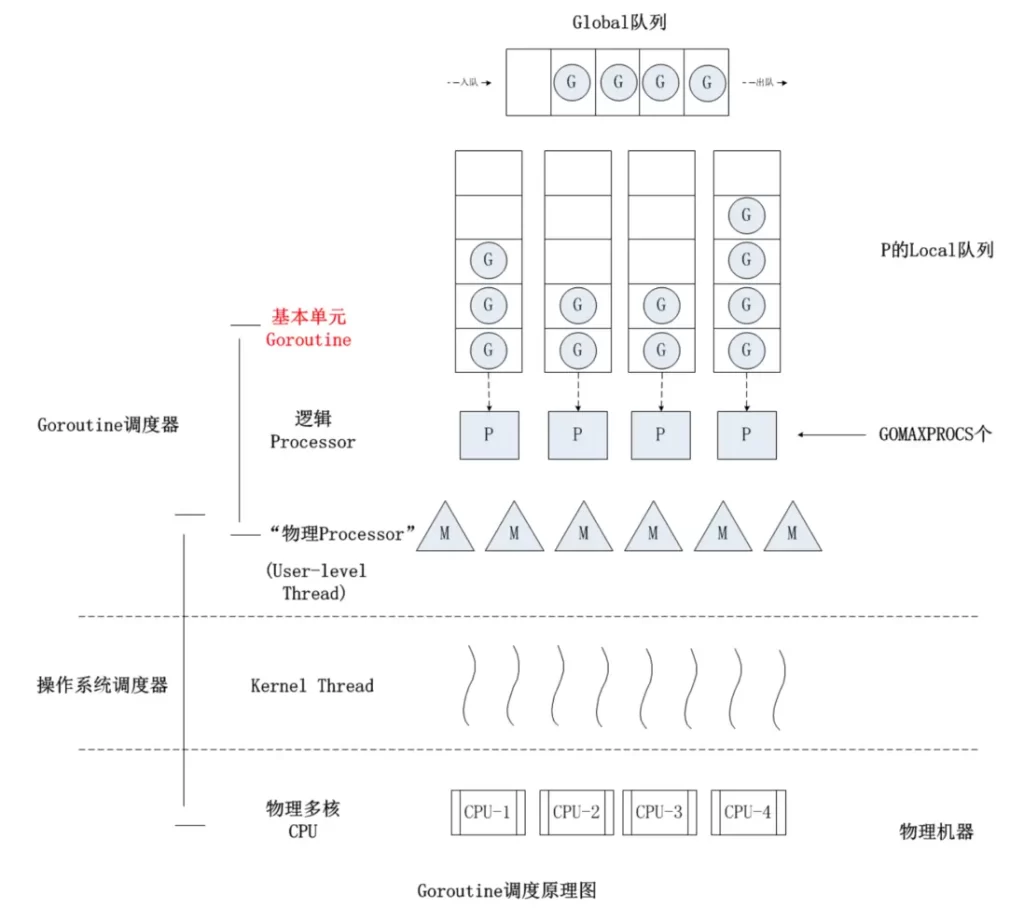
3. Preemptive scheduling
The implementation of the GPM model is a major improvement for Go scheduler, but Scheduler still has a headache, that is, it does not support preemptive scheduling. As a result, once an infinite loop or permanent loop code logic appears in a G, then G will be permanently occupied. For the P and M assigned to it, other Gs located in the same P will not be scheduled and will starve to death. What’s more serious is that when there is only one P (GOMAXPROCS=1), other Gs in the entire Go program will “starve to death”.
The principle of this preemptive scheduling is to add an extra piece of code at the entrance of each function or method to give the runtime a chance to check whether preemptive scheduling needs to be performed.
5. In-depth understanding of GPM model
1. Basic concepts
1. Global queue: stores G waiting to be run; 2. P 's local queue: similar to the global queue, it also stores G waiting to be run, and the number of storage does not exceed 256 ; 3. G: Groutine coroutine, the most basic unit of the scheduling system, has pointers, stacks, and context for running functions; 4. P : Processor, a scheduling logical processor, with various G object queues, linked lists, some caches and states. The number of P determines the maximum number of parallel Gs in the system; All Ps are created when the program starts and are saved in the array. The default is equal to the number of CUP cores, and there are at most GOMAXPROCS (configurable); 5. M: represents the executor of the actual work, corresponding to the thread at the operating system level. Each M is like a hard-working worker, finding runnable G from various queues;
Here is a picture that can vividly illustrate their relationship:
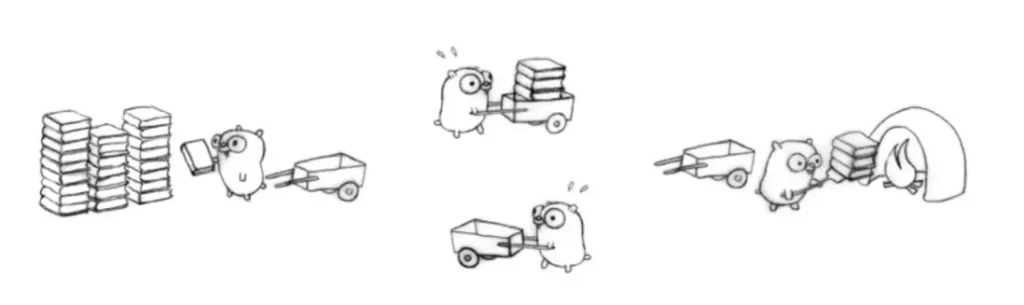
a mole uses a cart to transport a pile of bricks to be processed. M can be regarded as the mole in the picture, P is the cart, and G is the bricks loaded in the cart.
The creation and scheduling cycle of goroutine is a production-consumption process. The operation of the entire go program is to continuously execute the production and consumption process of goroutine.
2. Scheduler design strategy
2.1. Reuse threads
Avoid frequent creation and destruction of threads, but reuse threads.
1) Work stealing mechanism:
When this thread has no G to run, it tries to steal G from P bound by other threads instead of destroying the thread.
2) Hand off mechanism:
When this thread is blocked due to G making a system call, the thread releases the bound P and transfers P to other idle threads for execution.
2.2. Utilizing parallelism
GOMAXPROCS sets the number of P. At most, GOMAXPROCS threads can be distributed on multiple CPUs and run simultaneously.
2.3. Preemption
When the Go program starts, the runtime will start an M named sysmon, which will regularly issue preemptive scheduling to long-running (>=10MS) G tasks to prevent other goroutines from starving to death.
3. Goroutine scheduling process
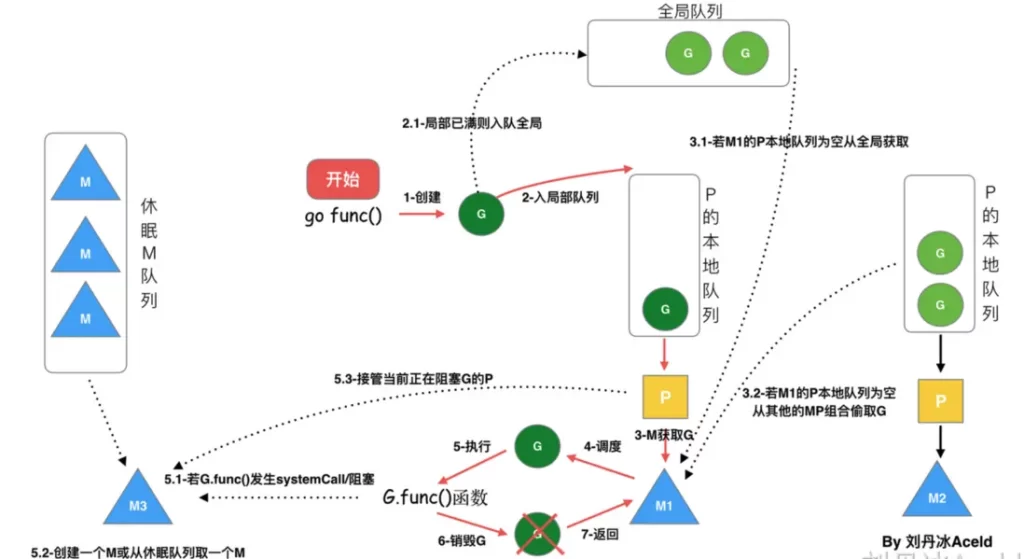
1. We create a goroutine through go func();
2. There are two queues that store G, one is the local queue of the local scheduler P and the other is the global G queue. The newly created G will first be saved in the local queue of P. If the local queue of P is full, it will be saved in the global queue;
3. G can only run in M. An M must hold a P. The relationship between M and P is 1:1;
4. The process of an M scheduling the execution of G is a loop mechanism. M will pop up an executable G from the local queue of P for execution. If the local queue of P is empty, it will look at the global queue, and there will be no global queue. An executable G will be stolen from other MP combinations for execution. If other queues cannot obtain M, they will spin;
5. If G is blocked on a channel operation or network I/O operation, G will be placed in a wait queue, and M will try to run the next runnable G of P. If P does not have a runnable G for M to run at this time, then M will unbind P and enter the suspended state.
When the I/O operation is completed or the channel operation is completed, the G in the waiting queue will be awakened, marked as runnable, and put into the queue of a certain P, bound to an M and then continue execution.
6. If G is blocked on a system call, not only will G be blocked, but M that executes G will also unbind P and enter the suspended state together with G. If there is an idle M at this time, then P will be bound to it and continue to execute other G; if there is no idle M, but there are still other G to execute, then the Go runtime will create a new M (thread ).
When the M system call ends, this G will try to obtain an idle P for execution and put it into the local queue of this P. If P cannot be obtained, then this thread M becomes dormant and joins the idle thread, and then this G will be put into the global queue.
7. When a new goroutine is created or multiple goroutines enter the waiting state, it will first determine whether there is a spinning M, and if there is, the spinning M will be used. When there is no spinning M, but there is a spinning M in the idle queue, An idle M will wake up M, otherwise a new M will be created.
4. Scheduler life cycle
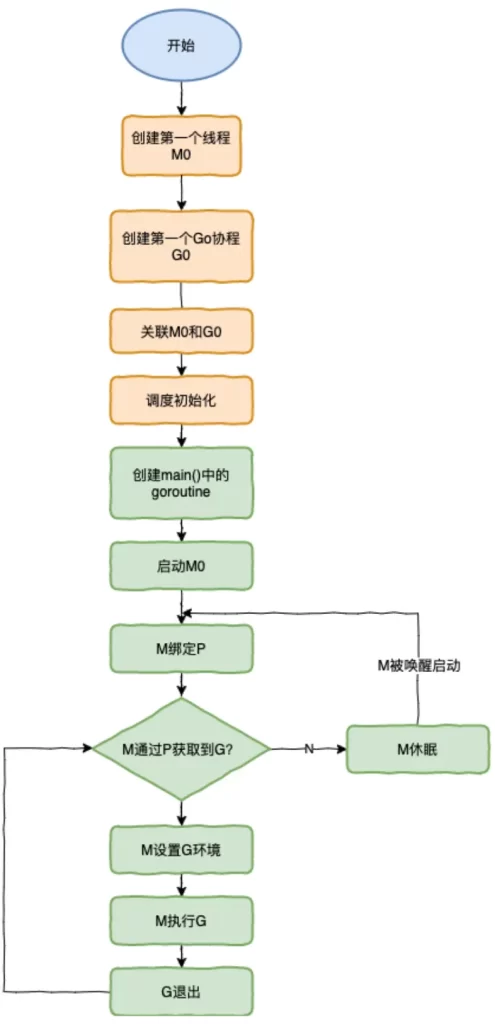
Special M0 and G0
M0
M0 is the main thread numbered 0 after starting the program. M0 is responsible for performing initialization operations and starting the first G. It is also responsible for doing specific things during the entire runtime – system monitoring (sysmon).
G0
G0 is the first gourtine created every time an M is started. G0 is only used for the G responsible for scheduling. G0 does not point to any executable function. Each M will have its own G0. The stack space of G0 will be used during scheduling or system calls. The G0 of global variables is the G0 of M0.
The running process of the scheduler is shown in the figure:
- The runtime creates the initial thread m0 and goroutine g0, and associates the two.
- Scheduler initialization: initialize m0, stack, garbage collection, and create and initialize a P list consisting of GOMAXPROCS Ps.
- There is also a main function in runtime – runtime.main. After the code is compiled, runtime.main will call main.main. When the program starts, a goroutine will be created for runtime.main. Call it main goroutine, and then add main goroutine. to P’s local queue.
- Start m0, m0 has been bound to P, will get G from P’s local queue, and get the main goroutine.
- G owns a stack, and M sets the operating environment based on the stack information and scheduling information in G.
- MrunG
- G exits, and returns to M again to obtain a runnable G. This repeats until main.main exits, runtime.main performs Defer and Panic processing, or calls runtime.exit to exit the program.
The life cycle of the scheduler almost takes up the life of a Go program. Before the goroutine of runtime.main is executed, preparations are made for the scheduler. The running of the goroutine of runtime.main is the real start of the scheduler. Until runtime.main End and end.
6. Summary
The essence of the Go scheduler is to allocate a large number of goroutine tasks to a small number of threads to run, using multi-core parallelism to achieve more powerful concurrency.
Reference materials:
Also talk about the goroutine scheduler
Golang’s coroutine scheduler principle and GMP design ideas
Goroutine scheduler
in-depth decryption of the scheduler of Go language
In-depth analysis of the GMP scheduler principle A high-performance goutine pool